Test Wars - Episode X: Attack of the Synthetic Clones
When Your Tests Infiltrate Production Like Rebel Spies (And Why Most of Them Fail)

TL;DR: Your staging environment cannot replicate the chaos of production. Synthetic monitoring—running automated tests against your live systems— is the answer, with the market exploding from $1.5B (2024) to a projected $6B+ by 2033. But first-generation synthetics are expensive, noisy failures. The winners are shifting from preventing failures (MTBF) to recovering fast (MTTR), and from superficial pings to AI-driven validation of actual business workflows. This is QA in Production, and it's no longer optional.
Episode X: The Lessons Compound
Ten episodes into this saga, we've deconstructed the myths of test automation, exposed the QA strategy deficit, and warned about AI hype. We've learned that production breaks despite perfect tests, that quality requires strategy before tools, and that the gap between staging and reality is where your business bleeds revenue.
Now we're bringing it all together: testing in production, with AI, done right.
This is the episode where staging environments finally lose. Where we stop pretending our sanitized test environments represent reality. Where we deploy clone troops—synthetic monitors—into production to patrol the only environment that actually matters: the one your customers use.
But here's the trap: most organizations are doing synthetic monitoring catastrophically wrong.
The 3 AM Production Paradox
Here's the nightmare that keeps CTOs awake: Your staging environment is pristine. Every test green. Your team deploys to production with swagger. Three hours later, checkout mysteriously fails for customers in Southeast Asia.
- The exact combination of microservice versions currently in production
- Real CDN configurations and latency patterns
- Actual third-party API behaviors under load
- The state of customer accounts from three migrations ago
- Traffic patterns from seventeen concurrent A/B tests
Your staging environment isn't production. It's a simulation. And simulations have fatal gaps that cost you customers, revenue, and reputation. One broken checkout flow at peak traffic can cost an e-commerce company $500,000 in an hour. One failed fund transfer can trigger regulatory scrutiny for a bank. One timeout in your SaaS onboarding can send a prospect to your competitor.
This gap between staging fantasy and production reality is where synthetic monitoring enters: automated tests that continuously patrol your live system, validating that critical business functions work correctly for real users, with real data, under real conditions.
Think of it as deploying clone troops into production—always watching, always testing, always ready to alert when something breaks.
But most organizations botch the deployment.
The Synthetic Menace: First-Generation Monitoring Fails
Martin Fowler defined synthetic monitoring clearly: run a subset of an application's automated tests against the live production system on a regular basis, pushing results into monitoring services that trigger alerts when failures occur.
The concept is sound. The typical implementation is a disaster.
Problem 1: Expensive Superficiality
You pay per test run, often for checks that amount to sophisticated pings. Does the homepage return 200? Congratulations, your server responded. Does a customer in Munich with a corporate discount code, a mixed cart of physical and digital products, and a payment method from 2019 successfully complete checkout during a flash sale?
Your test has no idea.
These superficial checks tell you the server is alive. They don't tell you if your business is functioning. You're paying for false confidence.
Problem 2: Happy Path Delusion
Static scripts test a single, sanitized workflow with a pristine test account while your actual customers juggle messy, real-world states. You're not testing production. You're testing a fairy tale version of production. Your test passes. Your customer fails. You never know until they churn.
Problem 3: Alert Fatigue (The Trust Killer)
Bad alerts train your team to ignore production issues. After a few false alarms, nobody trusts the monitoring anymore—leaving you blind when real outages occur.
The Philosophy That Changes Everything: MTTR vs MTBF
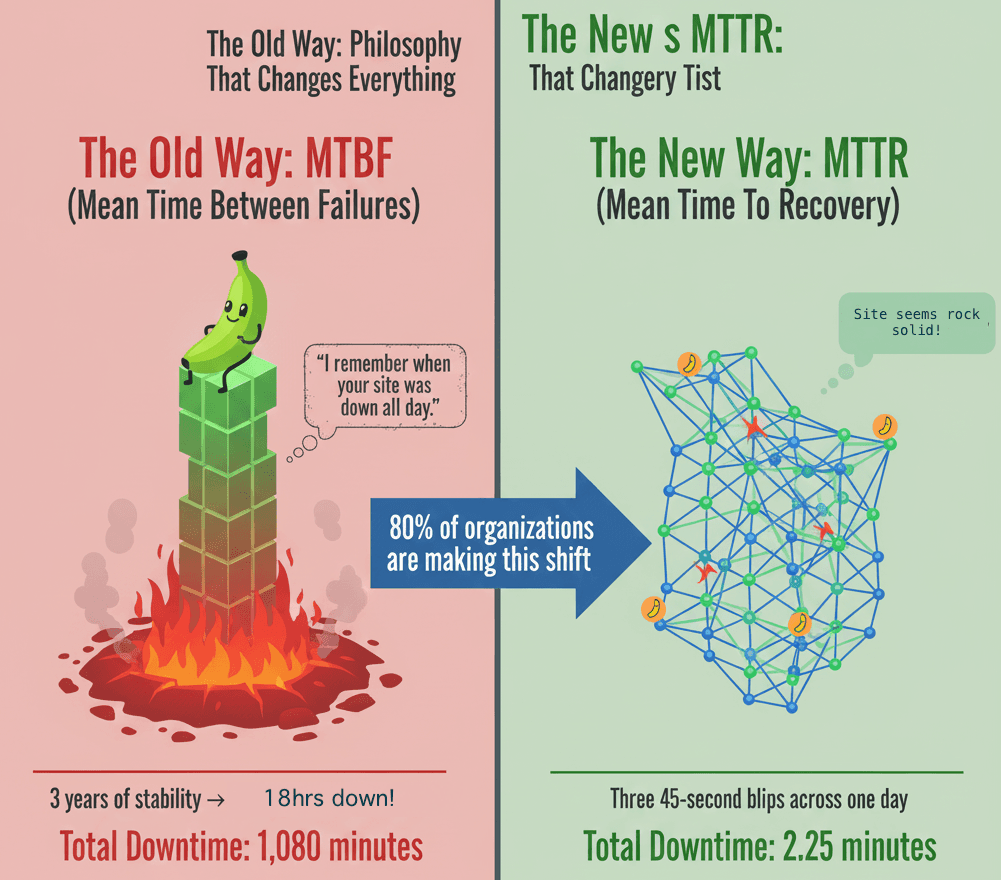
Traditional operations optimized for MTBF: prevent failures from reaching production. DevOps flipped this: for most failure types, MTTR is strategically more valuable. Failure is inevitable in complex systems; the only question is how fast you detect and recover.
The Business Mathematics
High MTTR strategy turns catastrophic day-long outages into brief blips few users notice. Synthetic monitoring is a primary weapon in that arsenal, catching issues within minutes of deployment instead of hours or days later.
What "Right" Actually Looks Like
The goal isn't to ping endpoints. It's to detect failing business requirements in production—QA in Production. Test real, multi-step user journeys that represent business value.
Real-World Example: The European Marketplace
A marketplace validates a favorites flow every 5 minutes: login, cleanup state, search, add favorites, check the counter. This monitors business value, not just uptime.
The Technical Reality: Implementation Details That Matter
1. Infrastructure Architecture
Ensure monitoring infrastructure is independent from the app.
- Cloud-based services
- Self-hosted environments
- Hybrid approach
2. Test Data Management
Manage synthetic data to avoid analytics pollution and enable concurrency.
3. Alert Configuration
Alert on consecutive failures, include context, use adaptive thresholds, and run multi-region.
4. Integration with Observability
Export metrics, integrate with incident management and CI/CD, and correlate logs.
When Synthetic Monitoring Goes Wrong: Failure Patterns
Common failure modes: alert fatigue, maintenance time sink, data pollution, monitoring everything.
The AI Transformation: Why Static Scripts Are Dying
AI enables self-healing tests, better root cause analysis, and adaptive noise filtering—reducing maintenance 60–80%.
But AI isn't strategy. You still choose workflows, data policies, thresholds, and interpret business impact.
The Implementation Playbook: Making This Real
Phase 1: Identify 5–10 critical workflows. Phase 2: Establish baseline monitors and tune. Phase 3: Integrate with deployments and incidents. Phase 4: Expand and optimize.
The Strategic Imperative: Why This Matters Now
Deployment velocity, system complexity, and customer expectations make production testing non-optional.
What We're Building at Desplega.ai
AI-native production testing: natural-language workflow definitions, self-healing production tests, business flow validation, and intelligent alerting.
One Thing to Remember: Test Business Requirements, Not Infrastructure
Continuously validate end-to-end business workflows in production. AI makes it feasible and essential.
References
- Fowler, Martin, Flávia Falé, and Serge Gebhardt. "Synthetic Monitoring." martinfowler.com
- Allspaw, John. "MTTR is more important than MTBF (for most types of F)." kitchensoap.com
- IMARC Group. "Synthetic Monitoring Market Size, Share & Forecast 2025-2033." imarcgroup.com
- Expert Market Research. "Synthetic Monitoring Market Size, Share & Analysis by 2034." expertmarketresearch.com
- DataIntelo. "Synthetic Monitoring As A Service Market Research Report 2033." dataintelo.com
- Mordor Intelligence. "Synthetic Monitoring Market - Size, Share & Industry Analysis." mordorintelligence.com
- Lebrero, Dan. "Testing or Monitoring? MTBF or MTTR? Make your choice!" danlebrero.com
- Checkly. "Synthetic Monitoring - Concepts, Benefits & Challenges." checklyhq.com
- Datadog. "Synthetic Testing: What It Is & How It Works." datadoghq.com
- Microsoft. "Synthetic Monitoring Tests - Engineering Fundamentals Playbook." microsoft.github.io
- Desplega.ai. "Business-Use: Track, validate, and visualize business flows in production applications." github.com/desplega-ai/business-use
Related Posts
Test Wars IX: The Code Wars - No-Code vs Vibe Coding
No-code platforms offer strategic escape from vibe coding chaos. Reduce technical debt, maintain quality, and achieve faster time-to-market in 2025's AI development era.
Test Wars Episode II: AI New Hope
Discover how AI is revolutionizing testing practices and bringing new hope to quality assurance teams worldwide.
The Compliance Testing Trap: Why Your SOC2 Audit Is Making Your Software Less Secure | desplega.ai
Your SOC2 badge helps close enterprise deals. It will not stop the breach that closes your company. Here is what the audit industry does not tell CTOs.